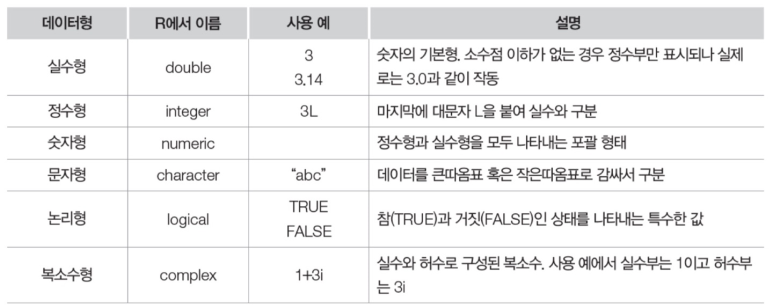
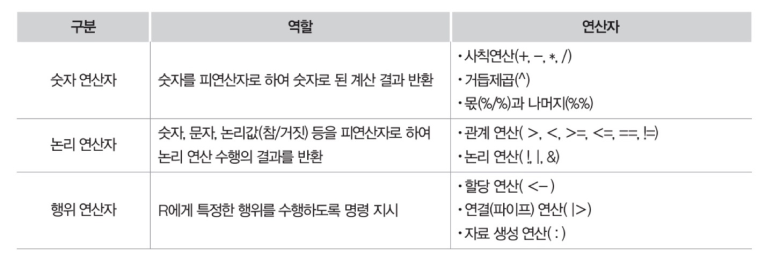
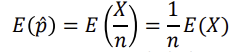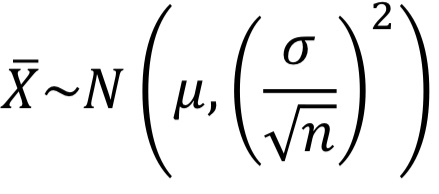01. 점추정과 구간추정추정 방법점추정(poing estimation): 표본으로부터 추정량을 이용하여 모수를 추정하는 방법. 표본추출에 따라 추정치가 달라지는 단점이 존재한다.점추정 예시로는 표본평균 구하기가 있다. 구간추정(interval estimation): 점추정을 중심에 두고 하한과 상한을 구하는 방법. 표준오차와 해당 추정치가 따르는 분포함수의 확률을 이용하여 신뢰구간을 구하는 과정이다.구간추정의 예시로는 ∝=0.05 : 95% 신뢰구간을 구하는 것이 있다. 중심극한정리에 의해 모집단이 𝑁(𝜇, 𝜎^2)인 정규분포를 따를 때, 표본평균은 𝑁( 𝜇, (𝜎 / sqr(𝑛))^2 ) 인 분포를 따르는 것을 확인할 수 있다. (표본평균의 표준오차 ≒ 표준편차) 모비율의 추정표본비율 : ..