4.1 csv
패키지 별 다양한 데이터 파일 읽기 및 쓰기 함수가 존재함.
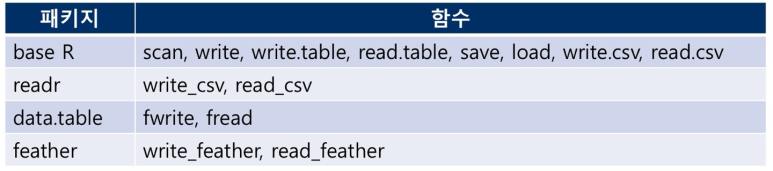
외부 데이터 파일 읽어오기 : csv 파일
- read.csv() 함수
- csv 파일을 읽기 위한 함수
- 주요 인수 - 읽어올 파일의 경로와 파일 이름, header, skip
- header : 데이터셋의 첫 줄을 열 이름인 헤더로 읽을 것인지의 여부를 TRUE와 FALSE 중 하나로 설정.(default는 TRUE)
- skip : 건너뛸 줄 수를 지정. 데이터 파일이 첫 줄부터 데이터셋으로 시작하지 않는 경우에 사용함.
4.2 함수를 활용한 데이터 분석
특성 찾기 함수
- mean(), median(), var(), sd() : 평균, 중앙값, 분산, 표준편차 구하기 함수
- fivenum(), diff() : 다섯자리 숫자요약과 사분위수 간의 거리 구하기 함수
* 다섯자리 숫자요약 : 최솟값, 제1사분위수, 중앙값, 제3사분위수, 최댓값
4.3 데이터 활용 기법
패키지 설치
- 패키지 : R의 기능을 이용하여 사용자들이 편리하게 데이터를 활용하기 위한 다양한 함수를 제공함.
- 패키지 설치 명령어 : install.packages("{설치할 패키지명}")
- 작업공간과 연결 : library() 함수 사용.
tidyverse 패키지
- ggplot, purrr, tibble, dplyr, tidyr, stringr, readr, forcats 패키지를 모두 한 번에 설치해줌.
dplyr 패키지
- 데이터를 다루는 문법으로 다음의 다섯가지 동사를 제공하여 데이터셋을 다루는데 도움을 주는 패키지로 다음은 각 동사를 구현한 대표적인 함수.
- filter() : 조건에 맞는 행 추출
- select() : 원하는 열 추출
- mutate() : 기존 열에 저장한 데이터를 이용하여 열 생성
- arrange() : 데이터 정렬
- summarise() : 데이터 요약
- 이 다섯가지 함수는 첫 번째 인수로 데이터프레임을 취하는 공통점이 있음.
- group_by() : dplyr 패키지에 Split을 위해 구현 되어 있는 함수로, 열의 값 별로 그룹을 만들고 각 그룹 별로 요약
- 위 다섯가지 기법을 결합하기 위해 하나의 흐름으로 만들어주는 파이프 연산자(%>%)를 사용한다.
- %>% 연산자는 좌측의 데이터프레임을 우측 함수의 첫 번째 인수로 전달한다.
* tibble
- R에서 사용하는 데이터 구조로 data.frame의 현대적 대안임.
- tidyverse 패키지에서 제공하는 기능.
- 데이터 분석을 위한 더 직관적이고 유연한 데이터 프레임을 제공함.
- 주요 특징
- 행과 열을 제한적으로 보여주어 긴 데이터를 다룰 때 가독성이 좋음.
- 열 이름이 더 유연하여, 공백이 있는 이름이나 숫자로 시작하는 이름도 허용.
- 기존 data.frame과 호환 가능.
- 문자형 데이터가 자동으로 팩터로 변환되지 않으며, 각 열의 데이터 타입을 유지함.
- 열 이름에 특수 문자나 공백이 들어가도 문제 없이 사용할 수 있으며, 백틱(`)을 사용해 접근 가능.
4.4 데이터 정리 - 데이터 과학자의 소양
깔끔한 데이터
- 변수마다 열을 가져야 한다.
- 관찰 대상마다 행을 가져야 한다.
- 각 값은 셀을 가져야 한다.
지저분한 데이터 유형
- 열 이름이 측정값인 경우
- 하나의 셀에 여러 값이 들어 있는 경우
- 측정값이 행과 열에 모두 포함된 경우
- 같은 데이터셋에 구분되지 않은, 전혀 다른 관찰 대상이 있는 경우
- 하나의 관찰 대상이 여러 데이터셋으로 나뉜 경우
Long Format/Wide Format
- Long Format : 새로운 데이터 저장으로 행이 증가
- Wide Format : 새로운 데이터 저장으로 열이 증가
- 관찰대상을 행으로 저장하는 깔끔한 데이터의 성질에 따라 Long Format 데이터가 깔끔한 데이터로 인식됨. 주로 Wide Format은 요약 데이터의 형태
4.5 문자 데이터
기본 문자 관련 함수

정규표현식
- 문자열의 패턴을 표현한 식
- tidyverse의 stringr 패키지가 지원하는 함수 사용
- str_detect() : 원하는 패턴의 존재 여부를 확인하는 함수(논리값 반환)
- str_extract() : 원하는 패턴을 추출하는 함수
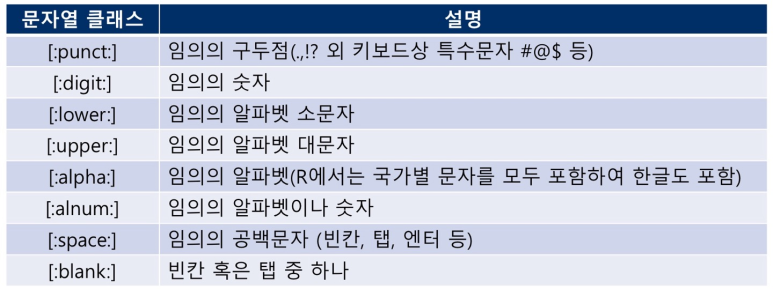
- 문자열 클래스 - [:클래스명:] 형태로 제공
- 문자로써 - 를 사용하기 위해서는 이스케이프 처리가 필요하다 : \
- 문자열을 나타내는 대괄호 사이에서도 이스케이프 문자 \를 사용해 문자열 내에서 문자가 아닌 이스케이프 기호로 사용하기 위해 겹쳐서 사용 \\
4.6 날짜 및 시간
- R은 날짜와 시간을 서로 다른 유형으로 저장
- as.Date() 함수를 이용하며 결과로 날짜형 데이터(객체) 반환
- class() 함수를 적용하면 객체의 유형을 알 수 있음
- 시간데이터
- POSIXt 객체
- POSIXct : ct는 continuous time으로 "년/월/일 시:분:초"와 같은 단일 문자열
- POSITlt : lt는 list time으로 연월일, 시분초 등의 개별 정보를 리스트로 저장
- attributes()와 attr() : 객체의 속성을 살피는 함수
- POSIXt 객체
- strptime() : 문자열에서 시간 정보 추출 함수
- 첫 번째 인수 : 시간 정보를 담고 있는 문자열 벡터
- 두 번째 인수 : 시간 정보의 포맷

- 두 시간 차이 연산자 -
- Date와 POSITt 클래스
- 시간 차이를 나타내는 객체인 diff 객체로 반환
- difftime() 함수
- 첫 번째 인수와 두 번째 인수 : Date 혹은 POSITt 클래스의 데이터를 전달받음.
- 인수 units : 초("secs"), 분("mins"), 시간("hours"), 일자("days"), 주("weeks") 단위로 차를 구함.
'⚡️ 전공수업 > R' 카테고리의 다른 글
| [R통계분석] R 데이터 시각화1 - ggplot2 기본 (0) | 2024.10.13 |
|---|---|
| [R통계분석] R 프로그래밍 - 반복문, 조건문 (0) | 2024.10.13 |
| [R통계분석] R 데이터 처리1 - 형태, 구조, 특성 (0) | 2024.10.12 |
| [R통계분석] R 기본 문법 (1) | 2024.10.12 |
| [R통계분석] 데이터 과학 개요 (1) | 2024.10.12 |